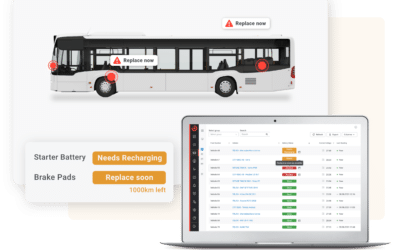
Large automotive and transportation companies have their own data science and research engineers and some decide to create their own machine learning platform to use the massive amount of vehicle data that is continuously being collected to automate anomaly and fault detection.
We have seen, and often very large ones, try this and fail. The complexity of a machine learning project is often underestimated, resulting in projects having difficulty in getting traction due to slow progress and inferior results.
In this article, we are going to share with you the lessons we learned while developing our machine learning platform, specifically designed for the automotive industry.
Lesson #1: You need more than just access to vehicle data to build great models
The first element that allows a machine learning system is indeed massive amounts of data. Data is the salvation of any machine learning product.
But it’s not just the amount of data that’s important, but also how relevant, diverse, clean and updated that data is.

Just as important as data are the labels that are used to train these models. Getting these labels is often a manual, time-consuming attempt. We improve our datasets with new information regarding vehicle data by leveraging our alert and user feedback module, making each client’s model a living system that improves over time.
Not only do we provide our customers in the transportation industry with a true head start in the slow and often expensive data labelling steps, but we also automate this critical process for them.
Lesson #2: The whole needs to be more than just the sum of the parts
We leverage hundreds of open-source components, but our platform also integrates several proprietary systems to coordinate them. We are not different from automotive manufacturers who all have access to the same parts.
You might be able to integrate the parts in a way that makes them function as a whole, which is already difficult, but although all companies can access the same components, not all companies build the best cars. And just like a car’s reliability is critical because it is expected to work without faults every time, a machine learning platform for anomaly detection is also either reliable or not useful at all.
Another similarity lies in the requirements that enable scale. Just like manufacturing and delivering small batches are not proof you can develop, ship and support millions of vehicles, scaling a machine learning platform from an R&D setting to a real-world scenario is a complex task.
Lesson #3: The current infrastructure will probably not be up to the task
The truth is that building AI is hard. The infrastructure required to handle large amounts of data, specifically in analytical workloads, has very different requirements than what most IT infrastructures are prepared for.
NoSQL databases, distributed computing frameworks and clusters of servers are parred for the course when implementing such a project, and the large ecosystem of tools to handle these problems is both a blessing and a curse for the systems architect.
Setting up this infrastructure can quickly become an abyss of incompatible services and configuration problems. Not only must a team have in-depth expertise in the core mechanisms of the technology, but it must also be able to develop across technologies that deliver all the necessary security and scalability that today’s enterprises require.
Lesson #4: Your platform must be a complete solution
Ensuring you achieve a complete solution is not straightforward. Building a machine learning product requires a pipeline of diverse actions that need to work together to take you from data to insight:

This process is usually highly recurrent, and each task can be very time-consuming. A stable integration of these tasks, coupled with tools that automate much of this work, highly accelerates the rate at which models can be developed and validated.
Our solution is a comprehensive machine learning toolbox, specifically developed for the automotive industry, designed to accelerate the development of custom anomaly detection systems for our clients.
Lesson #5: Don’t underestimate how long it can take to build
It’s very common for teams starting out to work on a model for months in R&D, only to later find out that the model does not work well in production. This often happens because models are built using static samples of data, while production environments provide a continuous stream of information.
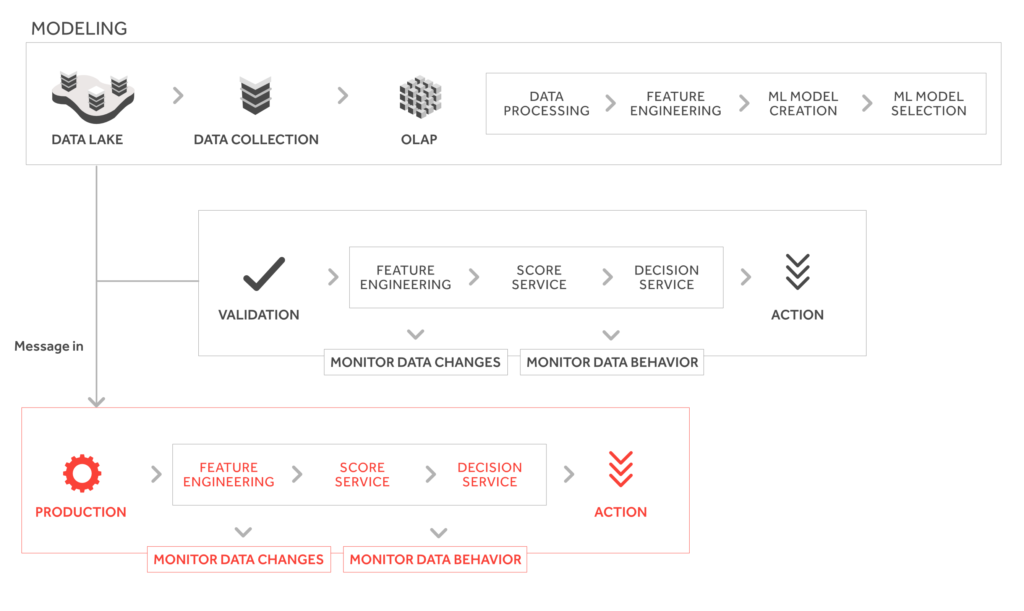
Crossing the line between R&D and production is serious for a machine learning product. A model’s output can be adequate when manually evaluating its performance against a static, well-defined and selected data set.
This scenario is very different from a production environment, where the model will have to cope with a continuous stream of data from multiple sources. This is why early indications of success are not a synonym of success, and it may take a long time to succeed in a sandbox environment only to then fail once moved to production. Time matters.
Lesson #6: Machine Learning Models degrade easily
The world we live in is not a static place. There are underlying trends affecting everything around us.
Road alterations, changes in traffic and weather variations among other factors, will all cause new driving patterns. This means that the assumptions made by models at the point of training do not hold for a long time and ultimately model outputs will deteriorate over time.
To account for this, we continuously monitor model performance to give our customers from the transportation industry, such as carriers or urban bus operators, the ability to track individual models to improve our predictive maintenance alerts over time. We take advantage of the customer feedback loop to continuously re-train our models, turning them into living systems that evolve and adapt to their environment.
However, most customers by themselves do not have large, diverse and specially labelled data ready to use to support the models’ learning. We have created an integrated data consortium where companies can opt-in to securely share their vehicle data, and leverage on improved models.
Lesson #7: Invest in the right provider, avoid vendor lock-in
If you invest in a product and later on decide to develop the AI models in-house and can’t without renouncing your previous investment, then you’ve made a poor decision in selecting the provider.
We are building the capabilities to extend our platform with your models. This means you will be able to build models in any language, using any library, and on any platform and then import these approaches to a platform that was built from the ground up, to handle anomaly and fault detection.
We do not believe in vendor lock-in. We believe in performance and pace as the criteria for a successful and long-term relationship with customers. The same performance and pace are of the essence to accomplish our mission to support the industry frontrunners driving a zero downtime future.
- Data-first strategy lowers cost per mile for bus operators - June 19, 2024
- SBS Transit Rolls Out Predictive Maintenancefor its Entire Bus Fleet Including Electric Buses - March 22, 2024
- News: Stratio and GreenRoad Announce Partnership - November 14, 2023